

In the fast-moving generative AI (Gen AI) market, two sets of recent announcements, although unrelated, portend why and how this nascent technology could evolve. The first set was Microsoft's Office 365 Copilot and Adobe's Firefly announcements, and the second was from Qualcomm, Intel, Google and Meta regarding running Gen AI models on edge devices. This evolution from cloud-based to Edge Gen AI is not only desirable but also needed, for many reasons, including privacy, security, hyper-personalization, accuracy, cost, energy efficiency, and more, as outlined in my earlier article.
While the commercialization of today's cloud-based Gen AI is in full swing, there are efforts underway to optimize the models built for power-guzzling GPU server farms to run on power-sipping edge devices with efficient mobile GPUs, Neural and Tensor processors (NPU and TPU). The early results are very encouraging and exciting.
Gen AI Extending to the Edge
Office 365 Copilot is an excellent application of Gen AI for productivity use cases. It will make creating attractive PowerPoint presentations, analyzing and understanding massive Excel spreadsheets, and writing compelling Word documents a breeze, even for novices. Similarly, Adobe's Firefly creates eye-catching images by simply typing what you need. As evident, both of these will run on Microsoft's and Adobe's clouds, respectively.
These tools are part of their incredibly popular suites with hundreds of millions of users. That means when these are commercially launched and customer adaption scales up, both companies will have to ramp up their cloud infrastructure significantly. Running Gen AI workload is extremely processor, memory, and power intensive—almost 10x more than regular cloud workloads. This will not only increase capex and opex for these companies but also significantly expand their carbon footprint.
One potent option to mitigate the challenge is to offload some of that compute to edge devices such as PCs, laptops, tablets, smartphones, etc. For example, run the compute-intensive "learning" algorithms in the cloud, and offload "inference" to edge devices when feasible. The other major benefits of running inference on edge are that it will address privacy, security, and specificity concerns and can offer hyper-personalization, as explained in my previous article.
This offloading or distribution could take many forms, ranging from sharing inference workload between the cloud and edge to fully running it on the device. Sharing workload could be complex as there is no standardized architecture exists today.
What is needed to run Gen AI on the edge?
Running inference on the edge is easier said than done. One positive thing going for this approach is that today's edge devices, be it smartphones or laptops, are powerful and highly power efficient, offering a far better performance-per-watt metric. They also have strong AI capabilities with integrated GPUs, NPUs, or TPUs. There is also a strong roadmap for these processor blocks.
Gen AI models come in different types with varying capabilities, including what kind of input they utilize and what they generate. One key factor that decides the complexity of the model and the processing power needed to run it is the number of parameters it uses. As shown in the figure below, the model size ranges from a few million to more than a trillion.
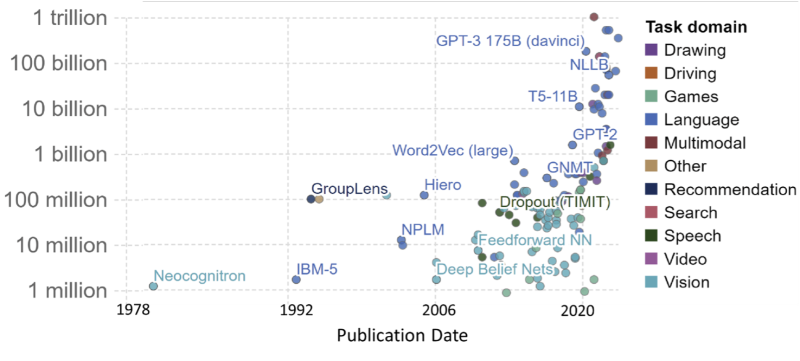
Gen AI models have to be optimized to be run on edge devices. The early demos and claims suggest that devices such as smartphones could run models typically one to several billion parameters today. Laptops, which can utilize discrete GPUs, can go even further and run models with more than 10 billion parameters now. These capabilities will continue to evolve and expand as devices become more powerful. However, the challenge is to optimize these models without sacrificing accuracy or with minimal or acceptable error rates.
Optimizing Gen AI models for the edge
There are a few things that help in optimizing the Gen AI model for the edge. First, in many use cases, inference is run for specific applications and domains. For example, inference models specific to the medical domain need fewer parameters than generic models. That should make running these domain-specific models on edge devices much more manageable.
Several techniques are used to optimize trained cloud-based AI models for edge devices. The top ones are quantization and compression. Quantization involves reducing the standard 32-bit floating models to 16-bit, 8-bit, or 4-bit integer models. This substantially reduces the processing and memory needed with minimal loss in accuracy. For example, Qualcomm's study has shown that these can improve performance-per-watt metric by 4-times, 16-times, and 64-times, respectively, with often less than 1% degradation in accuracy, depending on the model type.
Compression is especially useful in video, images, and graphics AI workloads where significant redundances between succussive frames exist. Those can be detected and not processed, which results in substantially reduced computing needs and improves efficiency. Many such techniques could be utilized for optimizing the Gen AI inference model for the edge.
There has already been considerable work and some early success for this approach. Meta's latest Llama 2 (Large Language Model Meta AI ) Gen model, announced on July 18th, 2023, will be available for edge devices. It supports 7 billion to 70 billion parameters. Qualcomm announced that it will make Llama 2-based AI implementations available on flagship smartphones and PCs starting in 2024. The company had demonstrated ControlNet, an image-to-image model currently in the cloud, running on Samsung Galaxy S23 Ultra. This model has 1.5 billion parameters. In Feb 2023, it also demonstrated Stable Diffusion, a popular text-to-image model with 1 billion parameters running on a smartphone. Intel showed Stable Diffusion running on a laptop powered by its Meteor Lake platform at Computex 2023. Google, when announcing its next-generation Gen AI PaLM 2 models during Google I/O 2023, talked about a version called Gecko, which is designed primarily for edge devices. Suffice it to say that much research and development is happening in this space.
In closing
Although most of the Gen AI today is being run on the cloud, it will evolve into a distributed architecture, with some workloads moving to edge devices. Edge devices are ideal for running inference, and models must be optimized to suit the devices' power and performance envelope. Currently, models with several billion parameters can be run on smartphones and more than 10 billion on laptops. Even higher capabilities are expected in the near future. There is already a significant amount of research on this front by companies such as Qualcomm, Intel, Google, and Meta, and there is more to come. It will be interesting to see how that progresses and when commercial applications running Gen AI on edge devices become mainstream.
If you want to read more articles like this and get an up-to-date analysis of the latest mobile and tech industry news, sign-up for our monthly newsletter at TantraAnalyst.com/Newsletter, or listen to our Tantra's Mantra podcast.
Industry Voices are opinion columns written by outside contributors — often industry experts or analysts — who are invited to the conversation by Silverlinings' editors. They do not represent the opinions of Silverlinings.